
S E P H ' S
[OS] 디스크 스케줄링 알고리즘 본문
디스크 스케줄링
보조기억장치는 현재 여러 가지 존재하지만 아직까지는 하드디스크가 주로 사용된다.

하드디스크의 구조는 앞서 살펴봤듯이 위 그림과 같다. 디스크에 접근하는 시간은 Seek Time(탐색시간) + rotational delay + transfer time으로 계산할 수 있는데, 이 중에서 seek time(head를 움직이는 시간)이 가장 크다.
현재 컴퓨터 환경은 대부분 다중 프로그래밍 환경이다. 그러므로 여러 프로세스가 메인 메모리에서 실행중에 있는데, 이러한 여러 프로세스가 동시에 디스크를 읽으려는 요청이 올 수 있다. 이와 같은 요청이 오면 디스크 역시 CPU와 같이 디스크 큐(disk queue)에서 요청을 저장해두고 이를 처리해야 한다.
여기서 컴퓨터의 성능을 위해 여러 요청들을 효율적으로 처리해야 한다. 디스크를 읽는 시간은 매우 오래 걸리는 작업이고 특히 탐색 시간이 오래 걸리므로 최대한 이 시간을 줄이는 것이 중요하다. 이러한 방법들을 디스크 스케줄링 알고리즘이라고 한다.
1. FCFS(First Come First Served)
이 방법은 어느 스케줄링 알고리즘 중에서도 존재하는 가장 간단하고 가장 공평한 알고리즘이다.
200 cylinder dist: 0, 1, 2, ..., 199
Disk queue: 98, 183, 37, 122, 14, 124, 65, 67
현재 헤드가 가리키는 실린더(cylinder) 위치: 53

예제를 그림으로 나타내면 위 그림과 같다. 가로축은 0번부터 199번까지 실린더의 위치를 나타낸다. 여기서 파란색 선이 disk queue를 FCFS 방법으로 처리한 결과이다.
헤드가 움직인 총 거리 = (98 - 53) + (183 - 98) + (183 - 37) + (122 - 37) + (122 - 14) + (124 - 14) + (124 - 65) + (67 - 65) = 640 cylinders
위 그림의 결과를 본 것처럼 큐에 들어온 순서가 큰 값, 작은 값이 반복한다면 헤드가 움직이는 거리가 매우 커짐을 알 수 있다.
2. SSTF(Shortest Seek Time First)
SSTF 스케줄링 알고리즘은 가장 짧은 탐색 시간을 먼저 선택하는 것이다. 다시 말하면 현재 헤드가 다음 요청을 처리하기 위해 움직여야 하는 거리가 가장 짧은 것을 선택하는 것이다.
200 cylinder dist: 0, 1, 2, ..., 199
Disk queue: 98, 183, 37, 122, 14, 124, 65, 67
현재 헤드가 가리키는 실린더(cylinder) 위치: 53
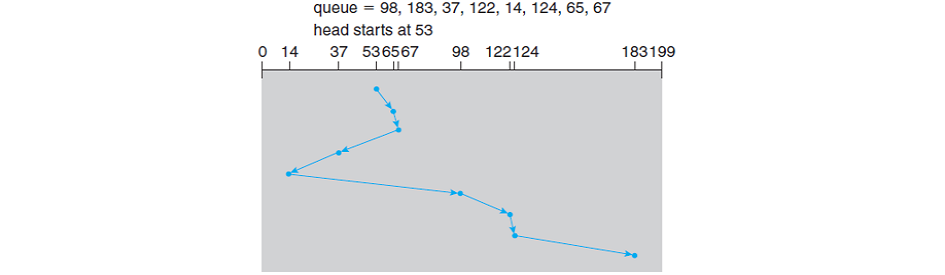
위 예제는 FCFS 스케줄링에서 다룬 예제와 같은 예제이다. 처음 헤드 위치를 53을 시작으로 disk queue에 있는 실린더 번호 중 53과 가장 가까운 65를 선택한다. 65번에서는 67을 선택하고 그 다음까지 같은 과정을 반복한다.
헤드가 움직인 총 거리 = (65 - 53) + (67 - 65) + (67 - 37) + (37- 14) + (98 - 14) + (122 - 98) + (124 - 122) + (183 - 124) = 236 cylinders
SSTF 스케줄링 알고리즘의 결과는 위 예제에서 FCFS 스케줄링 보다 훨씬 적은 수의 실린더를 움직이는 것을 볼 수 있다. 하지만 이 스케줄링의 가장 큰 단점은 기아(starvation)이 발생할 수 있다. disk queue에는 지속적으로 새로운 프로세스의 요청이 들어오기 때문에 헤드와 멀리 떨어져 있는 실린더는 끝내 수행하지 못하는 현상이 발생하는데, 이를 starvation이라고 한다.
그리고 SSTF 스케줄링 현재와 가장 가까운 실린더를 선택한다고 해서 최적의 알고리즘은 아니다. 위 예제에서도 가장 처음 위치에서 65가 아닌 37번으로 이동한 뒤에 SSTF 알고리즘을 실행하면 208 cyliners 가 나온다.
3. Scan
헤드가 지속적으로 디스크를 앞뒤로 검사하는 것이다. 그래서 헤드가 앞으로 스캔할 때(번호가 작은 실린더 방향)와 뒤로 스캔할때 (번호가 큰 실린더 방향) 선택하는 실린더가 다르다.
200 cylinder dist: 0, 1, 2, ..., 199
Disk queue: 98, 183, 37, 122, 14, 124, 65, 67
현재 헤드가 가리키는 실린더(cylinder) 위치: 53
스캔 방향: 0번 방향으로 움직임(번호가 작은 실린더 방향)
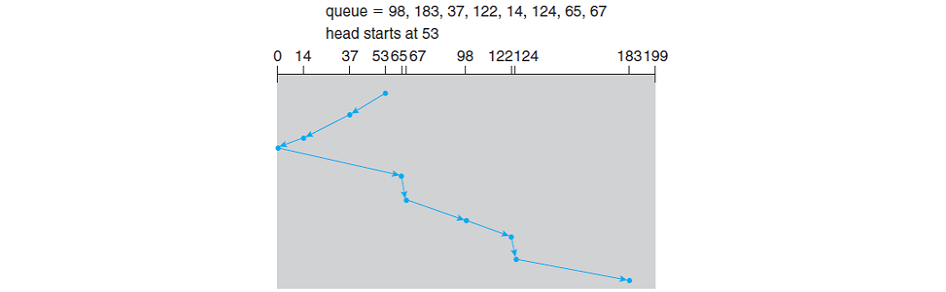
위 결과에서 볼 수 있듯이 스캔 방향이 0번 실린더 방향이므로 53번에서 작은 번호의 실린더로 향한뒤 큰 번호 실린더로 움직인 것을 볼 수 있다.
헤드가 움직인 총 거리 = (53 - 37) + (37 - 14) + (14 - 0) + (65 - 0) + (67 - 65) + (98 - 67) + (122 - 98) + (124 - 122) + (183 - 124) = 236 cylinders
일반적으로 프로세스들이 디스크에 요청할 때 그 위치를 종합해보면 실린더에 고루 퍼져있다. 그러므로 Scan 알고리즘 처럼 앞뒤로 움직이는 것이 아니라 처음부터 한 방향으로 끝까지 움직이고 다시 처음으로 되돌아가서 같은 방향으로 끝까지 움직이는 것이 더욱 효과적이다. 이러한 아이디어로 나온 것이 Circular Scan 스케줄링 알고리즘이다.
4. Scan Variants
1. C-Scan
이 방식은 위에서 말한 Circular Scan 스케줄링 알고리즘이다. 즉 한 방향으로 계속 움직이는 것이 마치 원형으로 움직인 것과 같은 모습이다. 움직이는 거리는 더 길어질 수 있지만 다시 처음 위치로 되돌아갈때는 데이터를 읽지 않으므로 더 빠른 속도로 움직일 수 있다.
2. Look
위 Scan 알고리즘 예제에서 0번 실린더가 존재하지 않지만 0번까지 가는 모습을 보았다. 이러한 비효율적인 움직임을 없애기 위해서는 존재하는 실린더의 최소 최대 범위만 움직이는 알고리즘을 Look 스케줄링 알고리즘이라고 한다. 하지만 이 범위를 알기 위해 미리 큐를 검사해야 한다.
3. C-Look
C-Look은 Circular Look을 말한다. Look은 위에서 Scan 스케줄링이 0번 부터 끝 실린더까지 움직이지 않고 존재하는 실린더의 최소최대 범위를 움직인다 했는데 C-Look은 이 범위에서 C-Scan 과 같이 한 방향으로만 움직이는 것을 말한다. 즉, 최대 실린더에서 최소 실린더 방향으로 움직인다고 하면 최소 범위에 도달하면 다시 최대 범위로 되돌아가서 같은 방향으로 움직인다.
5. Elevator Alogrithm
Elevator Algorithm은 Scan 과 파생되어 나온 알고리즘(C-scan, Look, C-Look)을 부르는 다른 용어이다. 위 Scan 스케줄링 알고리즘 예제 그림을 90도로 회전하면 엘리베이터의 모습과 유사하여 붙여진 이름이다.
'CS > OS' 카테고리의 다른 글
| [OS] 파일 할당 (0) | 2023.12.13 |
|---|---|
| [OS] 프레임 할당 (0) | 2023.12.13 |
| [OS] 페이지 교체 알고리즘 (0) | 2023.12.13 |
| [OS] 가상메모리 (0) | 2023.12.11 |
| [OS] 세그멘테이션 (0) | 2023.11.29 |



